使用 Dask Delayed 处理自定义工作负载
目录
在线 Notebook
您可以在在线会话中运行此 Notebook ![]() ,或在 Github 上查看它。
,或在 Github 上查看它。
使用 Dask Delayed 处理自定义工作负载¶

因为并非所有问题都适用于数据帧
本 Notebook 展示了如何使用 dask.delayed 来并行化通用 Python 代码。
Dask.delayed 是一种简单而强大的并行化现有代码的方式。它允许用户将函数调用延迟到一个具有依赖关系的任务图中。Dask.delayed 不提供像 Dask.dataframe 那样花哨的并行算法,但它确实让用户完全控制他们想要构建的内容。
像 Dask.dataframe 这样的系统就是用 Dask.delayed 构建的。如果你的问题可以并行化,但不像一个大数组或一个大数据帧那么简单,那么 dask.delayed 可能是你的正确选择。
启动 Dask 客户端以查看仪表板¶
启动 Dask 客户端是可选的。它将提供一个仪表板,这对于了解计算过程很有用。
当您在下方创建客户端时,仪表板的链接将可见。我们建议在您使用 Notebook 的同时,将仪表板打开在屏幕的一侧。这可能需要一些精力来安排您的窗口,但在学习时同时看到它们两者非常有用。
[1]:
from dask.distributed import Client, progress
client = Client(threads_per_worker=4, n_workers=1)
client
[1]:
客户端
Client-ec34dddc-0ddf-11ed-9937-000d3a8f7959
| 连接方法: Cluster 对象 | 集群类型: distributed.LocalCluster |
| 仪表板: http://127.0.0.1:8787/status |
集群信息
LocalCluster
e6e6b388
| 仪表板: http://127.0.0.1:8787/status | 工作节点 1 |
| 总线程数 4 | 总内存: 6.78 GiB |
| 状态: 运行中 | 使用进程: 是 |
调度器信息
调度器
Scheduler-ffcae259-51e4-486c-b3c6-364f64c20517
| 通信地址: tcp://127.0.0.1:39483 | 工作节点 1 |
| 仪表板: http://127.0.0.1:8787/status | 总线程数 4 |
| 启动时间: 刚刚 | 总内存: 6.78 GiB |
工作节点
工作节点:0
| 通信地址: tcp://127.0.0.1:40171 | 总线程数 4 |
| 仪表板: http://127.0.0.1:39167/status | 内存: 6.78 GiB |
| Nanny: tcp://127.0.0.1:41859 | |
| 本地目录: /home/runner/work/dask-examples/dask-examples/dask-worker-space/worker-bc95ewcw | |
创建简单函数¶
这些函数执行简单的操作,例如将两个数字相加,但它们会随机休眠一段时间以模拟实际工作。
[2]:
import time
import random
def inc(x):
time.sleep(random.random())
return x + 1
def dec(x):
time.sleep(random.random())
return x - 1
def add(x, y):
time.sleep(random.random())
return x + y
我们可以像下面的普通 Python 函数一样运行它们
[3]:
%%time
x = inc(1)
y = dec(2)
z = add(x, y)
z
CPU times: user 63.7 ms, sys: 9.27 ms, total: 73 ms
Wall time: 1.96 s
[3]:
3
它们一个接一个地按顺序运行。但请注意,前两行 inc(1) 和 dec(2) 彼此不依赖,如果足够聪明,我们本来可以并行调用它们。
使用 Dask Delayed 注解函数使其惰性化¶
我们可以对函数调用 dask.delayed 使其惰性化。它们不会立即计算结果,而是将我们要计算的内容记录为一个任务,放入稍后将在并行硬件上运行的任务图中。
[4]:
import dask
inc = dask.delayed(inc)
dec = dask.delayed(dec)
add = dask.delayed(add)
现在调用这些惰性函数几乎是免费的。我们只是在构建一个图。
[5]:
x = inc(1)
y = dec(2)
z = add(x, y)
z
[5]:
Delayed('add-06d4e85b-8b4e-4b7c-89d1-410e5876095b')
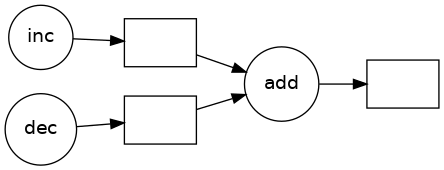
并行运行¶
当你想要将结果作为普通的 Python 对象时,调用 .compute()
如果你在上面启动了 Client(),那么你可能想在计算过程中查看状态页面。
[7]:
z.compute()
[7]:
3
并行化普通 Python 代码¶
现在我们在普通的 for 循环 Python 代码中使用 Dask。这会生成任务图而不是直接执行计算,但看起来仍然像我们之前的代码。Dask 是一种方便的方式,可以为现有工作流添加并行性。
[8]:
zs = []
[9]:
%%time
for i in range(256):
x = inc(i)
y = dec(x)
z = add(x, y)
zs.append(z)
CPU times: user 117 ms, sys: 4.68 ms, total: 121 ms
Wall time: 115 ms
[10]:
zs = dask.persist(*zs) # trigger computation in the background
为了加快速度,添加更多工作节点。
(尽管我们仍然只在本地机器上工作,但在使用实际集群时这更实用)
[11]:
client.cluster.scale(10) # ask for ten 4-thread workers
通过查看 Dask 仪表板,我们可以看到 Dask 将这项工作分散到我们的集群中,管理负载均衡、依赖关系等。
自定义计算:树状求和¶
作为一个非平凡算法的例子,考虑经典的树状规约。我们通过嵌套的 for 循环和一些普通的 Python 逻辑来实现这一点。
finish total single output
^ / \
| c1 c2 neighbors merge
| / \ / \
| b1 b2 b3 b4 neighbors merge
^ / \ / \ / \ / \
start a1 a2 a3 a4 a5 a6 a7 a8 many inputs
[12]:
L = zs
while len(L) > 1:
new_L = []
for i in range(0, len(L), 2):
lazy = add(L[i], L[i + 1]) # add neighbors
new_L.append(lazy)
L = new_L # swap old list for new
dask.compute(L)
[12]:
([65536],)
如果您正在查看仪表板的状态页面,那么您可能需要注意两件事
红色条表示工作节点间通信。它们发生在不同工作节点需要合并其中间值时
开始时有很多并行性,但随着我们到达树的顶部,工作量减少,并行性也随之减少。
或者,您可能想导航到仪表板的图页面,然后再次运行上面的单元格。您将能够在计算过程中看到任务图的演变。