在大型数据集上训练模型
在线 Notebook
您可以在在线会话中运行此 notebook ![]() ,或者在 Github 上查看。
,或者在 Github 上查看。
在大型数据集上训练模型¶
scikit-learn 中的大多数估计器都设计用于处理 NumPy 数组或 scipy 稀疏矩阵。这些数据结构必须能放入单台机器的 RAM 中。
在 Dask-ML 中实现的估计器可以很好地与 Dask 数组和 DataFrame 配合使用。这些数据结构可以远大于单台机器的 RAM。它们可以分布在机器集群的内存中。
[1]:
%matplotlib inline
[2]:
from dask.distributed import Client
# Scale up: connect to your own cluster with more resources
# see https://dask.org.cn/en/latest/setup.html
client = Client(processes=False, threads_per_worker=4,
n_workers=1, memory_limit='2GB')
client
[2]:
客户端
Client-a42f0f17-0de1-11ed-a66b-000d3a8f7959
| **连接方法:** Cluster object | **集群类型:** distributed.LocalCluster |
| **仪表盘:** http://10.1.1.64:8787/status |
集群信息
LocalCluster
770098da
| **仪表盘:** http://10.1.1.64:8787/status | 工作节点 1 |
| 总线程数 4 | **总内存:** 1.86 GiB |
| **状态:** 运行中 | **使用进程:** False |
调度器信息
调度器
Scheduler-09a424d6-c74b-456d-8b3c-65109da5de8c
| **通信:** inproc://10.1.1.64/9835/1 | 工作节点 1 |
| **仪表盘:** http://10.1.1.64:8787/status | 总线程数 4 |
| **启动时间:** 刚才 | **总内存:** 1.86 GiB |
工作节点
工作节点:0
| **通信:** inproc://10.1.1.64/9835/4 | 总线程数 4 |
| **仪表盘:** http://10.1.1.64:33217/status | **内存:** 1.86 GiB |
| **Nanny:** 无 | |
| **本地目录:** /home/runner/work/dask-examples/dask-examples/machine-learning/dask-worker-space/worker-by3a7q7t | |
[3]:
import dask_ml.datasets
import dask_ml.cluster
import matplotlib.pyplot as plt
在此示例中,我们将使用 dask_ml.datasets.make_blobs 来生成一些随机的 dask 数组。
[4]:
# Scale up: increase n_samples or n_features
X, y = dask_ml.datasets.make_blobs(n_samples=1000000,
chunks=100000,
random_state=0,
centers=3)
X = X.persist()
X
[4]:
|
我们将使用 Dask-ML 中实现的 k-means 对点进行聚类。它使用了 k-means||(读作:“k-means parallel”)初始化算法,该算法比 k-means++ 具有更好的扩展性。所有的计算,无论是在初始化期间还是之后,都可以并行完成。
[5]:
km = dask_ml.cluster.KMeans(n_clusters=3, init_max_iter=2, oversampling_factor=10)
km.fit(X)
/usr/share/miniconda3/envs/dask-examples/lib/python3.9/site-packages/dask/base.py:1283: UserWarning: Running on a single-machine scheduler when a distributed client is active might lead to unexpected results.
warnings.warn(
[5]:
KMeans(init_max_iter=2, n_clusters=3, oversampling_factor=10)
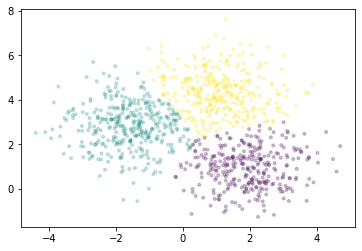
我们将绘制一个点样本,并根据每个点所属的聚类进行着色。
[6]:
fig, ax = plt.subplots()
ax.scatter(X[::1000, 0], X[::1000, 1], marker='.', c=km.labels_[::1000],
cmap='viridis', alpha=0.25);
对于 Dask-ML 中实现的所有估计器,请参阅API 文档。