分块集成方法
目录
分块集成方法¶
Dask-ML提供了一些集成方法,这些方法针对dask.array和dask.dataframe的分块结构进行了定制。基本思想是将某个子估计器的一个副本拟合到dask数组或DataFrame的每个块(或分区)上。由于每个块都适合内存,子估计器只需处理内存中的数据结构,例如NumPy数组或pandas DataFrame。它也会相对快速,因为每个块都适合内存,并且我们无需在集群上的工作节点之间移动大量数据。最终我们得到一个模型集成:训练数据集中每个块对应一个模型。
在预测时,我们将集成中所有模型的结果结合起来。对于回归问题,这意味着对每个子估计器的预测结果取平均值。对于分类问题,每个子估计器进行投票,并将结果组合起来。有关如何组合的详细信息,请参阅 https://scikit-learn.cn/stable/modules/ensemble.html#voting-classifier。有关平均集成方法为何有用的总体概述,请参阅 https://scikit-learn.cn/stable/modules/ensemble.html。
至关重要的是,数据集中的值分布在各分区之间应相对均匀。否则,在数据的任何给定分区上学习到的参数对于整个数据集而言将是糟糕的。稍后将详细展示这一点。
让我们随机生成一个示例数据集。在实践中,您会从存储中加载数据。我们将创建一个具有10个块的dask.array。
[1]:
from distributed import Client
import dask_ml.datasets
import dask_ml.ensemble
client = Client(n_workers=4, threads_per_worker=1)
X, y = dask_ml.datasets.make_classification(n_samples=1_000_000,
n_informative=10,
shift=2, scale=2,
chunks=100_000)
X
/usr/share/miniconda3/envs/dask-examples/lib/python3.9/site-packages/dask/base.py:1283: UserWarning: Running on a single-machine scheduler when a distributed client is active might lead to unexpected results.
warnings.warn(
[1]:
|
分类¶
子估计器应是一个已实例化的、兼容scikit-learn API的估计器(任何实现了fit / predict API的对象,包括管道)。它只需要处理内存中的数据集。我们将使用sklearn.linear_model.RidgeClassifier。
为了得到正确的输出形状,我们要求您为分类问题提供classes参数,可以在创建估计器时提供,如果子估计器也需要classes参数,也可以在.fit中提供。
[2]:
import sklearn.linear_model
subestimator = sklearn.linear_model.RidgeClassifier(random_state=0)
clf = dask_ml.ensemble.BlockwiseVotingClassifier(
subestimator,
classes=[0, 1]
)
clf
[2]:
BlockwiseVotingClassifier(classes=[0, 1],
estimator=RidgeClassifier(random_state=0))
我们可以正常训练。这将独立地将subestimator的一个克隆版本拟合到X和y的每个分区上。
[3]:
clf.fit(X, y)
所有拟合好的估计器都可以通过.estimators_访问。
[4]:
clf.estimators_
[4]:
[RidgeClassifier(random_state=0),
RidgeClassifier(random_state=0),
RidgeClassifier(random_state=0),
RidgeClassifier(random_state=0),
RidgeClassifier(random_state=0),
RidgeClassifier(random_state=0),
RidgeClassifier(random_state=0),
RidgeClassifier(random_state=0),
RidgeClassifier(random_state=0),
RidgeClassifier(random_state=0)]
这些是不同的估计器!它们在不同的数据批次上进行了训练,并学习到了不同的参数。我们可以绘制前两个模型学到的coef_的差异来可视化这一点。
[5]:
import matplotlib.pyplot as plt
import numpy as np
[6]:
a = clf.estimators_[0].coef_
b = clf.estimators_[1].coef_
fig, ax = plt.subplots()
ax.bar(np.arange(a.shape[1]), (a - b).ravel())
ax.set(xticks=[], xlabel="Feature", title="Difference in Learned Coefficients");
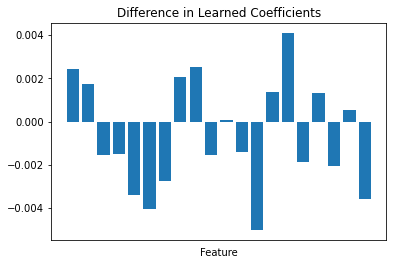
尽管如此,支持整个过程的假设是数据分布在各分区之间相对均匀。集成中每个成员学习到的参数应该相对相似,因此当应用于相同数据时,将给出相对相似的预测结果。
当您进行predict时,结果将与您进行预测的输入数组具有相同的分块模式(这不必与训练数据的分区匹配)。
[7]:
preds = clf.predict(X)
preds
[7]:
|
这会生成一系列任务,它们会:
为每个子估计器(我们示例中有10个)调用
subestimator.predict(chunk)将这些预测结果连接在一起
以某种方式将预测结果平均化为单个总体预测
我们使用了默认的voting="hard"策略,这意味着我们只选择获得最高票数的类别。如果前两个子估计器为第一行选择了类别0,而另外八个选择了类别1,则该行的最终预测结果将是类别1。
[8]:
preds[:10].compute()
[8]:
array([0, 1, 0, 0, 1, 0, 1, 1, 1, 1])
使用voting="soft"时,只要子估计器具有predict_proba方法,我们就可以访问predict_proba。这些子估计器应该经过良好校准,这样预测结果才有意义。有关更多信息,请参阅概率校准。
[9]:
subestimator = sklearn.linear_model.LogisticRegression(random_state=0)
clf = dask_ml.ensemble.BlockwiseVotingClassifier(
subestimator,
classes=[0, 1],
voting="soft"
)
clf.fit(X, y)
[10]:
proba = clf.predict_proba(X)
proba[:5].compute()
[10]:
array([[8.52979639e-01, 1.47020361e-01],
[1.32021045e-06, 9.99998680e-01],
[8.66086090e-01, 1.33913910e-01],
[8.78266251e-01, 1.21733749e-01],
[1.28333552e-01, 8.71666448e-01]])
这里的阶段与voting="hard"情况类似。只是现在不是取多数投票,而是对每个子估计器预测的概率进行平均。
回归¶
回归方法非常相似。主要区别在于没有投票;来自估计器的预测结果总是通过平均来汇总。
[11]:
X, y = dask_ml.datasets.make_regression(n_samples=1_000_000,
chunks=100_000,
n_features=20)
X
[11]:
|
[12]:
subestimator = sklearn.linear_model.LinearRegression()
clf = dask_ml.ensemble.BlockwiseVotingRegressor(
subestimator,
)
clf.fit(X, y)
[13]:
clf.predict(X)[:5].compute()
[13]:
array([-149.72693022, 340.45467686, -118.23129541, 327.7418488 ,
-148.9040957 ])
与Dask-ML通常一样,评分是以并行方式进行的(如果您连接到集群,则会在集群上分布式执行)。
[14]:
clf.score(X, y)
[14]:
1.0
数据非均匀分布的风险¶
最后,必须再次强调,在使用这些集成方法之前,您的数据应在各分区之间均匀分布。如果数据不是均匀分布的,那么更好的做法是只从每个分区采样行,然后将一个单一分类器拟合到采样数据上。我们所说的“均匀”并不是指“来自均匀概率分布”。只是说数据的分布方式不应该存在明显的分区模式。
让我们用一个例子来证明这一点。我们将生成一个在各分区之间具有明显趋势的数据集。这可能代表一些非平稳时间序列,尽管它也可能发生在其他上下文中(例如,按地理、年龄等划分的数据)。
[15]:
import dask.array as da
import dask.delayed
import sklearn.datasets
[16]:
def clone_and_shift(X, y, i):
X = X.copy()
X += i + np.random.random(X.shape)
y += 25 * (i + np.random.random(y.shape))
return X, y
[17]:
# Make a base dataset that we'll clone and shift
X, y = sklearn.datasets.make_regression(n_features=4, bias=2, random_state=0)
# Clone and shift 10 times, gradually increasing X and y for each partition
Xs, ys = zip(*[dask.delayed(clone_and_shift, nout=2)(X, y, i) for i in range(10)])
Xs = [da.from_delayed(x, shape=X.shape, dtype=X.dtype) for x in Xs]
ys = [da.from_delayed(y_, shape=y.shape, dtype=y.dtype) for y_ in ys]
X2 = da.concatenate(Xs)
y2 = da.concatenate(ys)
让我们绘制一些样本点,并根据数据来自哪个分区进行着色。
[18]:
fig, ax = plt.subplots()
ax.scatter(X2[::5, 0], y2[::5], c=np.arange(0, len(X2), 5) // 100, cmap="Set1",
label="Partition")
ax.set(xlabel="Feature 0", ylabel="target", title="Non-stationary data (by partition)");
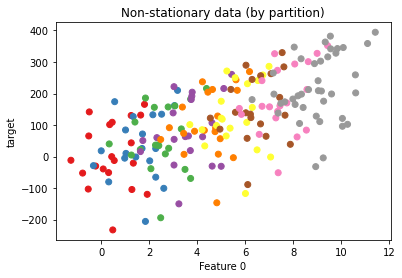
现在让我们拟合两个估计器:
一个在整个数据集上运行的
BlockwiseVotingRegressor(它在每个分区上拟合一个LinearRegression)一个在整个数据集的样本上运行的
LinearRegression
[19]:
subestimator = sklearn.linear_model.LinearRegression()
clf = dask_ml.ensemble.BlockwiseVotingRegressor(
subestimator,
)
clf.fit(X2, y2)
[20]:
X_sampled, y_sampled = dask.compute(X2[::10], y2[::10])
subestimator.fit(X_sampled, y_sampled)
[20]:
LinearRegression()
比较评分,我们发现采样数据集表现得更好,尽管训练数据较少。
[21]:
clf.score(X2, y2)
[21]:
-11.8766583738708
[22]:
subestimator.score(X2, y2)
[22]:
0.09217254441717304
这表明需要确保您的数据在各分区之间相对均匀。即使包含标准控制措施来规范产生非平稳数据的潜在因素(例如时间趋势分量、时间序列数据的差分、地理区域的哑变量等),如果您的数据集是按非均匀变量分区的,这些措施也是不够的。您仍然需要在拟合之前对数据进行混洗(shuffle),或者只采样一部分数据,并在适合内存的子样本上拟合子估计器。