2019 年 Dask 用户调查结果
目录
2019 年 Dask 用户调查结果¶
本 notebook 展示了 2019 年 Dask 用户调查的结果,该调查于今年夏天早些时候进行。感谢所有花时间填写调查问卷的人!这些结果有助于我们更好地了解 Dask 社区,并将指导未来的开发工作。
原始数据以及初步分析可在以下 binder 中找到
![]()
如果您在数据中发现任何内容,请告知我们。
亮点¶
我们收到了 259 份调查回复。总的来说,我们发现调查受访者非常关注文档的改进、易用性(包括部署便捷性)以及扩展性。尽管 Dask 汇集了许多不同的社区(大型数组用户与大型 dataframe 用户、传统 HPC 用户与云原生资源管理器用户),但在对 Dask 来说最重要的事情上,大家普遍达成了一致。
现在我们将逐一审视一些单独的问题项,重点介绍特别有趣的结果。
[1]:
%matplotlib inline
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import textwrap
import re
api_choices = ['Array', 'Bag', 'DataFrame', 'Delayed', 'Futures', 'ML', 'Xarray']
cluster_manager_choices = [
"SSH",
"Kubernetes",
"HPC",
"My workplace has a custom solution for this",
"Hadoop / Yarn / EMR",
]
def shorten(label):
return textwrap.shorten(label, 50)
def fmt_percent(ax):
ticklabels = ['{:,.2f}%'.format(x) for x in ax.get_xticks()]
ax.set_xticklabels(ticklabels)
sns.despine()
return ax
df = (
pd.read_csv("data/2019-user-survey-results.csv.gz", parse_dates=['Timestamp'])
.replace({"How often do you use Dask?": "I use Dask all the time, even when I sleep"}, "Every day")
)
您如何使用 Dask?¶
关于学习资源,几乎所有受访者都使用文档。
[2]:
ax = (
df['What Dask resources have you used for support in the last six months?']
.str.split(";").explode()
.value_counts().head(6)
.div(len(df)).mul(100).plot.barh()
);
fmt_percent(ax).set(title="Support Resource Usage");
/tmp/ipykernel_10046/4183606021.py:24: UserWarning: FixedFormatter should only be used together with FixedLocator
ax.set_xticklabels(ticklabels)

大多数受访者至少偶尔使用 Dask。幸运的是,我们有相当一部分受访者只是在了解 Dask,但也花了时间填写了调查问卷。
[3]:
usage_order = [
'Every day',
'Occasionally',
'Just looking for now',
]
ax = df['How often do you use Dask?'].value_counts().loc[usage_order].div(len(df)).mul(100).plot.barh()
fmt_percent(ax).set(title="How often do you use Dask?");
/tmp/ipykernel_10046/4183606021.py:24: UserWarning: FixedFormatter should only be used together with FixedLocator
ax.set_xticklabels(ticklabels)

我很好奇随着用户经验的增长,学习资源的使用情况如何变化。我们可能会期望那些刚刚了解 Dask 的人从 examples.dask.org 开始,在那里他们无需安装即可尝试 Dask。
[4]:
resources = df['What Dask resources have you used for support in the last six months?'].str.split(";").explode()
top = resources.value_counts().head(6).index
resources = resources[resources.isin(top)]
m = (
pd.merge(df[['How often do you use Dask?']], resources, left_index=True, right_index=True)
.replace(re.compile("GitHub.*"), "GitHub")
)
fig, ax = plt.subplots(figsize=(10, 10))
sns.countplot(hue="What Dask resources have you used for support in the last six months?",
y='How often do you use Dask?',
order=usage_order,
data=m, ax=ax)
sns.despine()
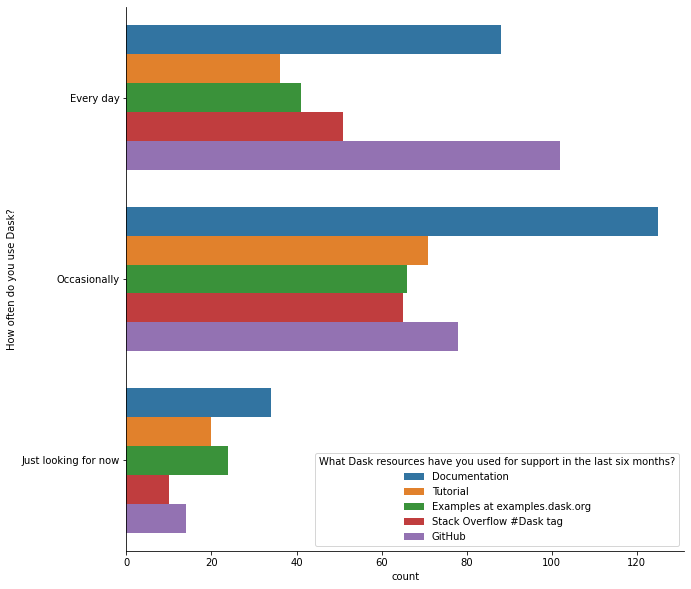
总的来说,文档在所有用户群体中仍然是首选。
Dask 教程和dask 示例的使用情况在各群体中相对一致。常规用户和新用户之间的主要区别在于,常规用户更有可能在 GitHub 上参与讨论。
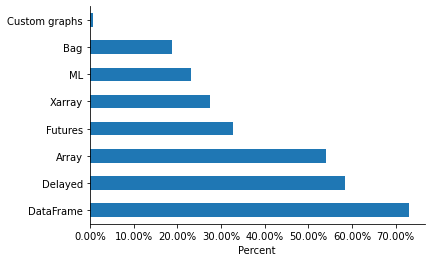
从 StackOverflow 问题和 GitHub issue 中,我们对库的哪些部分被使用有一个模糊的概念。调查显示(至少对我们的受访者来说)DataFrame 和 Delayed 是最常用的 API。
[5]:
api_counts = (
df['Dask APIs'].str.split(";").explode().value_counts()
.div(len(df)).mul(100)
)
ax = api_counts.sort_values().nlargest(8).plot.barh()
fmt_percent(ax).set(xlabel="Percent")
sns.despine();
/tmp/ipykernel_10046/4183606021.py:24: UserWarning: FixedFormatter should only be used together with FixedLocator
ax.set_xticklabels(ticklabels)
[6]:
print("About {:0.2%} of our respondests are using Dask on a Cluster.".format(df['Local machine or Cluster?'].str.contains("Cluster").mean()))
About 65.49% of our respondests are using Dask on a Cluster.
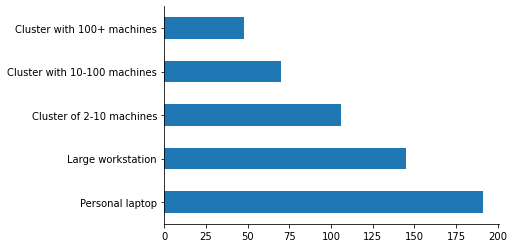
但大多数受访者也在他们的笔记本电脑上使用 Dask。这突显了 Dask 向下扩展的重要性,无论是用于使用 LocalCluster 进行原型设计,还是使用 LocalCluster 或任一单机调度器进行核外分析。
[7]:
order = [
'Personal laptop',
'Large workstation',
'Cluster of 2-10 machines',
'Cluster with 10-100 machines',
'Cluster with 100+ machines'
]
df['Local machine or Cluster?'].str.split(";").explode().value_counts().loc[order].plot.barh();
sns.despine()
大多数受访者至少在部分时间以交互方式使用 Dask。
[8]:
mapper = {
"Interactive: I use Dask with Jupyter or IPython when playing with data;Batch: I submit scripts that run in the future": "Both",
"Interactive: I use Dask with Jupyter or IPython when playing with data": "Interactive",
"Batch: I submit scripts that run in the future": "Batch",
}
ax = df["Interactive or Batch?"].map(mapper).value_counts().div(len(df)).mul(100).plot.barh()
sns.despine()
fmt_percent(ax)
ax.set(title='Interactive or Batch?');
/tmp/ipykernel_10046/4183606021.py:24: UserWarning: FixedFormatter should only be used together with FixedLocator
ax.set_xticklabels(ticklabels)

大多数受访者认为,增加文档和示例是对项目最有价值的改进。这一点在新用户中尤为突出。但即使是在每天使用 Dask 的人中,认为“更多示例”比“新功能”或“性能改进”更有价值的人也更多。
[9]:
help_by_use = (
df.groupby("How often do you use Dask?")['Which would help you most right now?']
.value_counts()
.unstack()
)
s = (
help_by_use
.style
.background_gradient(axis="rows")
.set_caption("Normalized by row. Darker means that a higher proporiton of "
"users with that usage frequency prefer that priority.")
)
s
[9]:
| 目前什么对您帮助最大? | 错误修复 | 更多文档 | 我所在领域的更多示例 | 新功能 | 性能改进 |
|---|---|---|---|---|---|
| 您使用 Dask 的频率是? | |||||
| 每天 | 9 | 11 | 25 | 22 | 23 |
| 目前只是了解 | 1 | 3 | 18 | 9 | 5 |
| 偶尔 | 14 | 27 | 52 | 18 | 15 |
也许某些 Dask API 的用户对整体的看法不同?我们根据 API 使用情况而非使用频率进行了类似的分析。
[10]:
help_by_api = (
pd.merge(
df['Dask APIs'].str.split(';').explode(),
df['Which would help you most right now?'],
left_index=True, right_index=True)
.groupby('Which would help you most right now?')['Dask APIs'].value_counts()
.unstack(fill_value=0).T
.loc[['Array', 'Bag', 'DataFrame', 'Delayed', 'Futures', 'ML', 'Xarray']]
)
(
help_by_api
.style
.background_gradient(axis="columns")
.set_caption("Normalized by row. Darker means that a higher proporiton of "
"users of that API prefer that priority.")
)
[10]:
| 目前什么对您帮助最大? | 错误修复 | 更多文档 | 我所在领域的更多示例 | 新功能 | 性能改进 |
|---|---|---|---|---|---|
| Dask API | |||||
| Array | 10 | 24 | 62 | 15 | 25 |
| Bag | 3 | 11 | 16 | 10 | 7 |
| DataFrame | 16 | 32 | 71 | 39 | 26 |
| Delayed | 16 | 22 | 55 | 26 | 27 |
| Futures | 12 | 9 | 25 | 20 | 17 |
| ML | 5 | 11 | 23 | 11 | 7 |
| Xarray | 8 | 11 | 34 | 7 | 9 |
没有什么特别突出。使用“futures”的用户(我们预计他们相对更高级)可能优先考虑功能和性能而非文档。但所有人都同意,更多示例是最高优先级。
常见功能请求¶
对于特定功能,我们列出了一些我们(作为开发者)认为可能很重要的事情。
[11]:
common = (df[df.columns[df.columns.str.startswith("What common feature")]]
.rename(columns=lambda x: x.lstrip("What common feature requests do you care about most?[").rstrip(r"]")))
counts = (
common.apply(pd.value_counts)
.T.stack().reset_index()
.rename(columns={'level_0': 'Question', 'level_1': "Importance", 0: "count"})
)
order = ["Not relevant for me", "Somewhat useful", 'Critical to me']
g = (
sns.FacetGrid(counts, col="Question", col_wrap=2, aspect=1.5, sharex=False, height=3)
.map(sns.barplot, "Importance", "count", order=order)
)
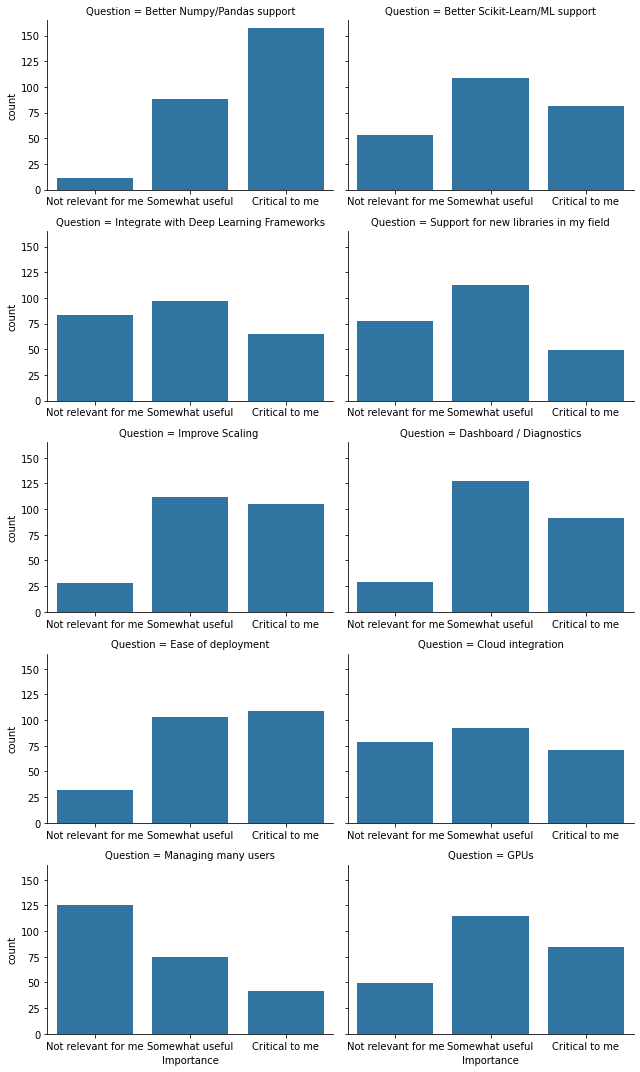
最突出的一点是,有多少人认为“更好的 NumPy/Pandas 支持”是“最关键的”。事后来看,最好能有一个后续的填空项,以了解每个受访者具体指的是什么。最简洁的解释是“覆盖更多 NumPy / pandas API”。
“易于部署”在受访者中被评为“对我最关键”的比例很高。事后来看,我注意到这里有些模糊不清。这是否意味着人们希望 Dask 更容易部署?还是意味着他们目前觉得易于部署的 Dask 至关重要?无论如何,我们都可以优先考虑部署的简便性。
相对较少的受访者关心诸如“管理大量用户”之类的事情,尽管我们预计这在系统管理员中会相对受欢迎,但系统管理员是一个更小的群体。
当然,对于那些将 Dask 推向极限的用户来说,“改进扩展性”至关重要。
您还使用哪些其他系统?¶
相对较高比例的受访者使用 Python 3(97%,而最近一次Python 开发者调查中为 84%)。
[12]:
df['Python 2 or 3?'].dropna().astype(int).value_counts(normalize=True).apply("{:0.2%}".format)
[12]:
3 97.29%
2 2.71%
Name: Python 2 or 3?, dtype: object
看到 SSH 是最受欢迎的“集群资源管理器”,我们有些惊讶。
[13]:
df['If you use a cluster, how do you launch Dask? '].dropna().str.split(";").explode().value_counts().head(6)
[13]:
SSH 98
Kubernetes 73
HPC resource manager (SLURM, PBS, SGE, LSF or similar) 61
My workplace has a custom solution for this 23
I don't know, someone else does this for me 16
Hadoop / Yarn / EMR 14
Name: If you use a cluster, how do you launch Dask? , dtype: int64
集群资源管理器与 API 使用情况如何比较?
[14]:
managers = (
df['If you use a cluster, how do you launch Dask? '].str.split(";").explode().dropna()
.replace(re.compile("HPC.*"), "HPC")
.loc[lambda x: x.isin(cluster_manager_choices)]
)
apis = (
df['Dask APIs'].str.split(";").explode().dropna()
.loc[lambda x: x.isin(api_choices)]
)
wm = pd.merge(apis, managers, left_index=True, right_index=True).replace("My workplace has a custom solution for this", "Custom")
x = wm.groupby("Dask APIs")["If you use a cluster, how do you launch Dask? "].value_counts().unstack().T
x.style.background_gradient(axis="columns")
[14]:
| Dask API | Array | Bag | DataFrame | Delayed | Futures | ML | Xarray |
|---|---|---|---|---|---|---|---|
| 如果您使用集群,您如何启动 Dask? | |||||||
| 自定义 | 15 | 6 | 18 | 17 | 14 | 6 | 7 |
| HPC | 50 | 13 | 40 | 40 | 22 | 11 | 30 |
| Hadoop / Yarn / EMR | 7 | 6 | 12 | 8 | 4 | 7 | 3 |
| Kubernetes | 40 | 18 | 56 | 47 | 37 | 26 | 21 |
| SSH | 61 | 23 | 72 | 58 | 32 | 30 | 25 |
HPC 用户是 dask.array 和 xarray 的相对重度用户。
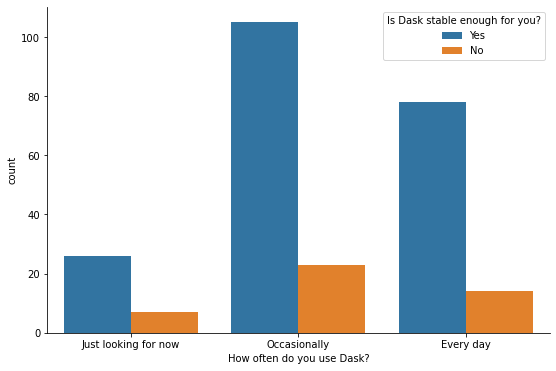
有些令人惊讶的是,Dask 的最重度用户认为 Dask 已经足够稳定。也许他们已经克服了 bug 并找到了解决方法(百分比按行归一化)。
[15]:
fig, ax = plt.subplots(figsize=(9, 6))
sns.countplot(x="How often do you use Dask?", hue="Is Dask stable enough for you?", data=df, ax=ax,
order=reversed(usage_order));
sns.despine()
要点总结¶
我们应优先改进和扩展我们的文档和示例。这可以通过 Dask 维护者向社区征集示例来完成。https://examples.dask.org.cn 上的许多示例是由使用 Dask 的领域专家开发的。
改进对更大问题的扩展性很重要,但我们不应为此牺牲单机使用场景。
交互式工作流和批量工作流都很重要。
Dask 的各个子社区相似之处多于不同之处。
再次感谢所有受访者。我们期待重复这一过程,以识别随时间变化的趋势。